Cued
A local sync engine for durable agent context, built around replayable messaging and contact data on-device.
Frontier models are materially better at long-horizon tasks, better at tool calling, better at subagents, and have destroyed virtually every benchmark we have thrown at them. Yet there has been very little improvement in personal AI use cases over the last year.1 We set out to investigate this question: even if the models are no longer the main bottleneck, why has there still been no real aha moment, beyond coding and computer use, for the average agent-enabled individual in daily tasks?
Our initial hypothesis was that we were simply getting context wrong. Essays on context graphs by Jaya Gupta, products like Inspect and Glass from Ramp, and the hundreds of “agents for work” startups funded on the intuition of mining process data for agent workflows all point in the same direction.23
However, most methods of context ingestion are dynamic -- meaning models have access to CLIs and MCPs to pull information from platforms like Gmail or WhatsApp, but (1) must do so every time a request is made and (2) do not save request results, which makes resolving information between contacts challenging.4 We believe that scraping is the easy part and persistent structured access is the hard part, but it makes model performance on important tasks way better.
We came to believe that context has to be pre-processed into a format that surfaces semantic information directly. So we built Cued: a local sync engine that pulls messaging and contact data from iMessage, WhatsApp, LinkedIn, Slack, and similar systems into a single local SQLite database that agents can query directly.
Fragmented private sources
Messaging is a natural first target because it requires resolving identity across platforms: knowing who is who, everywhere. Cued is an experiment to demonstrate that aggregating and pre-processing context is the path to extracting real value from agents. As models continue to improve, we believe the systems that win will be the ones giving agents durable, high-trust, native access to context, meaning SQLite and bash, rather than asking them to assemble it on the fly.5
This post will outline (1) installing and using Cued, (2) a technical overview, and (3) takeaways.
Using cued
Installation
Download the latest Cued.dmg from GitHub Releases, drag Cued.app into /Applications, and open it. Follow onboarding and approve the requested macOS permissions. Runtime state stays local under ~/.cued/.
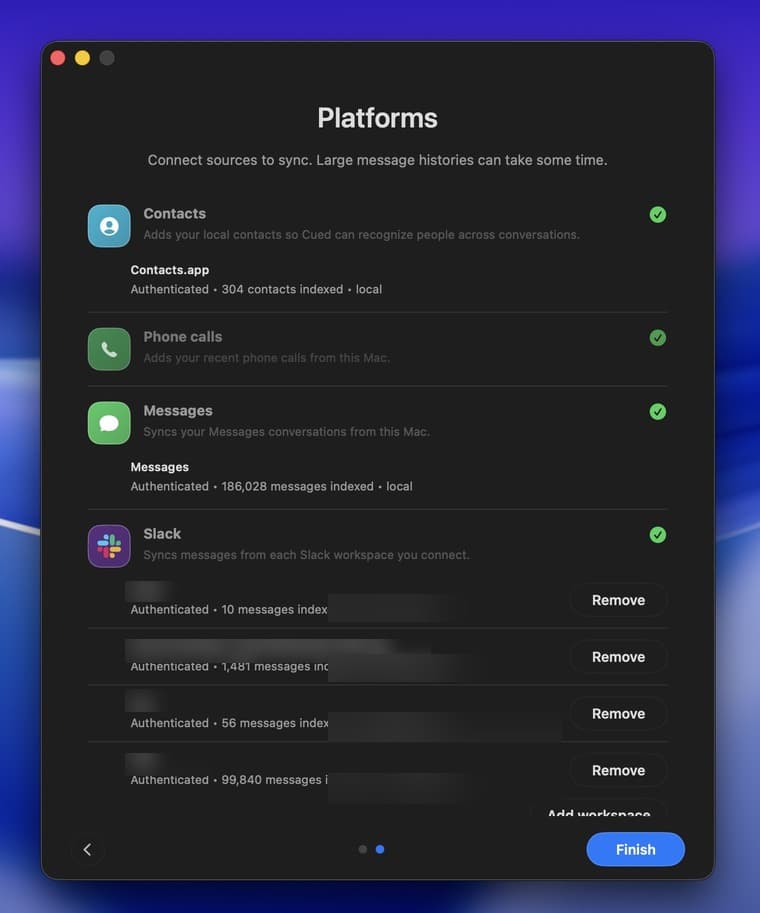
Favorites
We have already found Cued to be quite useful in conjunction with Codex Automations and OpenClaw. Some examples are worth trying out.
People-focused use cases
- enrich LinkedIn contacts, then determine who to reach out to given some goal around a domain or network
- identify who has been met in the last six months and should be followed up with
- take a written article and determine the ten people who should receive it
- determine who a new person should be introduced to
- build a contact graph around who can intro whom to a target person or company
Scheduling and logistics
- “Are you free at 5pm?”
- “What did we decide on?”
Marketing and follow-up
- personalized check-ins
- drip sequences for messages
- follow-ups that are grounded in actual relationship history
Across all of these, the bottleneck is much less about text generation than it is about reconstructing the relevant state across fragmented conversations and contacts.
Cued architecture
SQLite > bash and local > cloud
The first question people ask is why this should be a database at all. Why not dump contacts and threads into markdown files and grep over them? That seems attractive for a pretty understandable reason. Each contact could be a markdown file with a summary and recent messages at the top, and an agent could pull the first few hundred lines to get up-to-date context on an individual. Relationship information and memories could then be stored as markdown and continuously rewritten over time.
We decided to use read-only SQLite for a few reasons.
- Agents do mess up, so read-only SQLite is a safer interface and makes corruption easier to avoid.
- Syncing becomes a real systems problem quickly. Once multiple hostile source systems are involved, joins, constraints, checkpoints, and a schema that can guarantee what data has been fetched and projected become crucial.
- From Vercel’s benchmarking in “Testing if Bash is all you need,” SQLite seems to be the more reliable choice.
The second, easier question is choosing local over cloud. Cued is meant to be a durable, high-trust context layer, and messaging plus contact data is sensitive, messy, and constantly changing. Keeping that state on device in ~/.cued/local.db makes the system easier to trust, inspect, and recover.
At runtime, Cued has three layers:
- a native macOS host for permissions, OS integration, and access to platform-local stores
- a daemon and CLI for sync orchestration and projection
- a single local SQLite database at
~/.cued/local.db
Database and platform architecture
Now we can walk through the most important parts of the sync daemon.
Ingestion from platforms is separate from the derived state an agent queries. Each platform integration produces raw events: an iMessage at 6pm from Theo, a contact update, a reaction, an attachment, or some other observed fact. Those events get written into an append-only log. A projection layer then turns them into canonical contacts, conversations, participants, messages, reactions, attachments, and timeline state.
This separation is structurally important because it enables replayability, checkpoints, and rebuilding state from the log after faulty syncs or duplicate fetches.
To do this, Cued is structured around a few core primitives: raw_events as the canonical ingest log, sync_checkpoints for source cursors, sync_scopes and sync_proofs for coverage, sync_runs and sync_run_errors for observability, and projection_state for tracking derived state.
Before
ok great, send it over
accepted your invitation
can intro you after demo
what did we decide?
After
The diagram shows the core shape: source observations flow into raw_events, sync metadata tracks coverage, and projection builds the tables agents actually read.
Second, we have to construct a per-platform sync integration. By platform, we mean any source system where personal context lives: iMessage, WhatsApp, Slack, Gmail, LinkedIn, Contacts, or eventually any app or website that produces useful relationship data. This is much harder than it seems. Each integration has to handle initial sync, maintain a cursor for recent syncs, and safeguard against failure cases. Each platform also has its own cursor model, data model, auth flow, rate limits, failure modes, and idea of what a conversation or identity means.
Each platform maintains a sync bundle with source accounts, raw events, an optional source cursor, and diagnostics. They are different acquisition layers feeding the same internal event system. The distinction between cursor and proof matters: a cursor says where a sync stopped, but a proof says what the agent can safely treat as complete.
The daemon then consumes those bundles in three stages: it ingests raw events into SQLite, projects them into canonical state, and exposes operational state through the CLI and daemon status surface.
One of the more important design decisions in Cued is that adapters do not write directly to canonical state. They only write observations. That means state can be replayed after a bug fix, rebuilt after a schema change, and corrected as the system improves. Backfill is useful and important.
This is the part that protects against a common failure mode in personal AI: presenting a fragment of reality as the whole truth. If the system cannot say what it has synced, what it has not synced, and where the evidence came from, the agent cannot know how much confidence to place in the answer.
The trust model is simple: agents can read broadly from local encrypted state, but writes should go through explicit commands with invariants built in.
Identity resolution is the core structuring problem
The core structuring problem in this category is identity resolution.Once messages and contacts from multiple systems are being aggregated, the question is no longer just whether a message can be retrieved. The harder question is whether the system can maintain a coherent view of people across fragmented sources. That includes contact resolution, enrichment, source relevance, and source priority. When do two handles actually refer to the same person? Which source should win when information conflicts? Which source is more recent? Which source is more authoritative? How should different platform-specific identities map into a single contact model without collapsing unrelated people together?
Sources
Cued contact
Maya ChenThis is where many personal AI systems quietly break. They treat sources as equally meaningful, joins as roughly safe, and retrieved context as interchangeable. In practice, this is exactly how an agent ends up confidently presenting a fragment of reality as the whole truth.
Messaging makes this obvious. The total amount of messages and contacts for most real users is much larger than a million tokens. In my case, I have 150k messages and 5k contacts. For any given task, relevant context is a genuine needle-in-a-haystack retrieval problem. Most messages and contacts are irrelevant, but the right combination of messages and insights across contacts is often what produces the correct answer.
Cued v1 is an attempt to make that context structured, local, and traceable enough for agents to use. It is not a finished CRM, but it points at one: a system where private and valuable context sources can be discovered and mapped into identity.
Takeaways
I think the future CRM problem can be boiled down to three things: context discovery, context structuring, and context sharing.
Cued v1 is mostly a proposal for context structuring. Once the data is local, you can either “tokenmaxx” and throw huge models at it, or run smaller RLM-style agents in parallel to turn messy context into structured contacts, conversations, memories, and relationship state. The important thing is that the structure is grounded in evidence and can be rebuilt when it is wrong.
Context discovery is the next layer. A future CRM should notice when you start using a new messaging app, newsletter, or forum, then create and maintain the integration needed to pull that surface into your local context graph.
This is where self-maintaining software matters. APIs change. Schemas change. A normal product needs an engineer to patch every connector. The long-term goal is that agents detect broken integrations, inspect the new schema, propose the adapter change, test it in a sandbox against old data, and show the diff before it touches the real database.
The unsolved part is context sharing. The primitive should not be sharing your entire personal context database; it should be: what am I allowed to share with this person, for this purpose, right now?
That means a few things:
- data stays local by default
- identity merges and memory writes need audit trails
- agents need human approval where trust and privacy matters
The other open problem is taste. Once a personal agent has structured context, it should not only know facts about your network. It should learn what you value, who you trust, what kinds of opportunities you care about, and what you would actually do. This is where real leverage will exist, multiplying your output automatically.
Notes
We define personal AI tasks to mean working with context from your messages, contacts, email, and notes all in one place, developing a model of you as a person, and acting on that model. ↩
Jaya Gupta and Ashu Garg’s AI’s trillion-dollar opportunity: Context graphs notably went viral on X for pointing at the same missing-context layer. ↩
Ramp’s background agent writeup also went viral. We suspect internal adoption is quite low and that some of this is closer to a hiring signal, which justifies the broader point about these tools not becoming indispensable in-house. ↩
Peter Steinberger of OAI and OpenClaw fame ships an insane number of PRs per day, but often without precision. Building context crawlers to index Discord messages, Slack messages, and emails is not enough when you need to resolve contacts across platforms and know who is who every time you scrape. Maintaining state and lookups requires durable engineering and will not be solved by throwing skills on a model. Crawlers are a useful start for sync engines, but not the end state of context capture. ↩
We have tried the personal assistant tools. They miss lots of context through MCP because other platforms are supposed to design schemas that are agent-native, but in practice this rarely happens. People mostly port HTTP APIs one-to-one into MCP endpoints. SQL and bash are the most flexible API, and in our internal evaluations they have far outperformed MCP. ↩